Nicole Drakos
Research Blog
Welcome to my Research Blog.
This is mostly meant to document what I am working on for myself, and to communicate with my colleagues. It is likely filled with errors!
This project is maintained by ndrakos
SED Pipeline Part II
In this post I outlined the new method for assigning SEDs to the galaxies, and tested it using a small parent catalog (16000 points). I had issues with low redshift data, but it is likely because the parent catalog did not sample this part of parameter space very well. In this post I am outlining the new parent catalog.
(Note, in the previous post I called the parent catalog the “base catalog”, but I decided “parent catalog” is clearer.)
Updated Parent Catalog
I made a parent catalog that has \(10^8\) points, sampled as follows:
- Mass: sampled \(\log_{10}( M_{\rm gal}/M_\odot )\) uniformly between 5 and 12
- Redshift: sampled \(z\) uniformly between 0 and 12
- SFR: from the mass-SFR relation
- Metallicity: from the fundamental-mass relation
- Gas Ionization: from the metallicity-\(U_S\) relation
- Dust: from a truncated normal distribution. Centred at 0 with standard deviation of 1, truncated between 0 and 4
- Age: samples \(\log_{10}({\rm age})\) uniformly between \(10^6\) years and the (age of universe-\(10^6\)) years
- Star-forming time: sampled \(\log_{10}(\tau/{\rm Gyr})\) uniformly between -1 and 2 (range of allowed values in FSPS)
Then given each of these, I calculated the following values with FSPS:
- SFR (note that this will NOT be consistent with the SFR above, used to give a reasonable range of metallicities)
- UV luminosity, \(M_{\rm UV}\)
- UV slope, \(\beta\)
Notes on Timing
From the previous post, I was unsure how long it would take for (1) create tree from the parent catalog and (2) calculate distances on tree. I looked into this a bit more.
- I found it took ~15 minutes to create a tree from the \(10^8\) points in the parent catalog. This will not be a problem.
- Calculating the distance on the tree for each object in the galaxy catalog will scale with number of objects, but I was unsure exactly how long this would take for different sized parent catalogs. I did a little testing on my laptop with one core, using the 10 nearest neighbours.
For the old parent catalog (with 16000 objects), I calculated it should be ~3 hours to find the nearest neighbours for the \(512^3\) simulations, and ~300 hrs for \(2048^3\) simulation. With the \(10^8\) parent catalog, I found it should be roughly 8 hours for the \(512^3\) simulation, and 800 hours for \(2048^3\) simulation.
Therefore this shouldn’t be limiting. If i can use 400 processors, it will take about 2 hours to get distances for all objects in 2048 sim, even with a \(10^8\) parent catalog.
Memory Issues
One problem that arose with using this larger parent catalog is memory issues.
I am running this on lux. Every node as 192 GB of memory and 40 cores.
Current Code
rank 0:
- loads the parent catalog
- sends a copy of the parent catalog to all the processors (this has to be split up since mpi4py has a maximum size it can send at once)
- reads in the galaxy catalog (e.g. masses, redshifts for each galaxy)
- splits the galaxy catalog among processors
All processors:
- make the k-d tree
- propose parameters for all galaxies assigned to it
- find nearest neighbours in tree
- uses weighted average in parent catalog to get FSPS params
- Calculate SED using FSPS parameters
Therefore, each node has a copy of
- the parent catalog (\(10^8 \times 10\)) floats. ~20 GB
- the tree object. This is created from 7 fields from parent catalog, and is roughly ~20 GB (note that the data in here overlaps with that in the parent catalog)
- part of the galaxy catalog (except for rank 0 which stores the whole galaxy catalog). For the \(2048^3\) simulation, this will be ~50 GB (if I load in all the fields, including e.g. halo properties and positions). For the \(512^3\) simulations it is about ~0.5 GB. It is worth it to note that the core doesn’t need all this information at once, unlike the tree data… I can load in a few galaxies at a time and then assign properties.
With this work flow, I would not want more than 2 tasks per node to avoid memory issues. Since i am limited to 16 nodes, this means ~32 processes (which is a lot slower than the 400 i was planning on using).
Possible solutions
I am going to look into two things.
First, I am running with a smaller parent catalog (with \(10^6\) galaxies) to test if I get an improvement in the SED assignments compared to the 16000 parent catalog I used before.
Secondly, I am going to restructure the code so that it uses less memory.
Results with smaller parent catalog
I took the first \(10^6\) items in parent catalog and reassigned SEDs on the \(512^3\) catalog. With the \(10^6\) catalog, I did not have any memory issues, and it took about 2 hours on 400 cores.
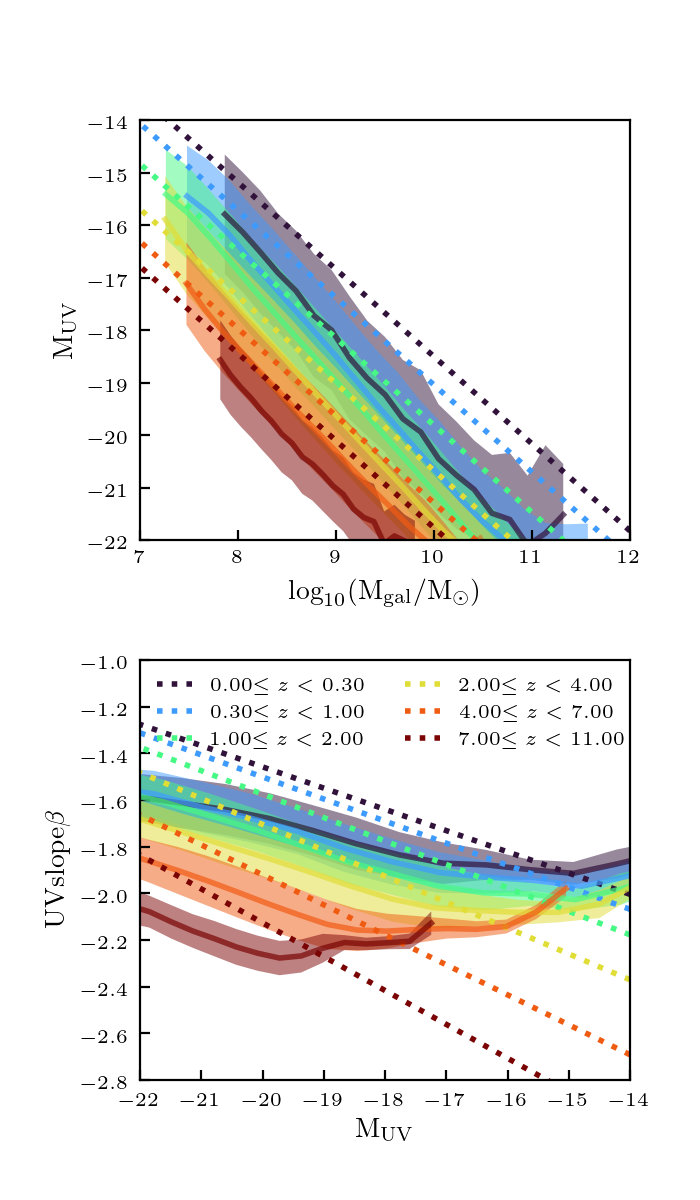
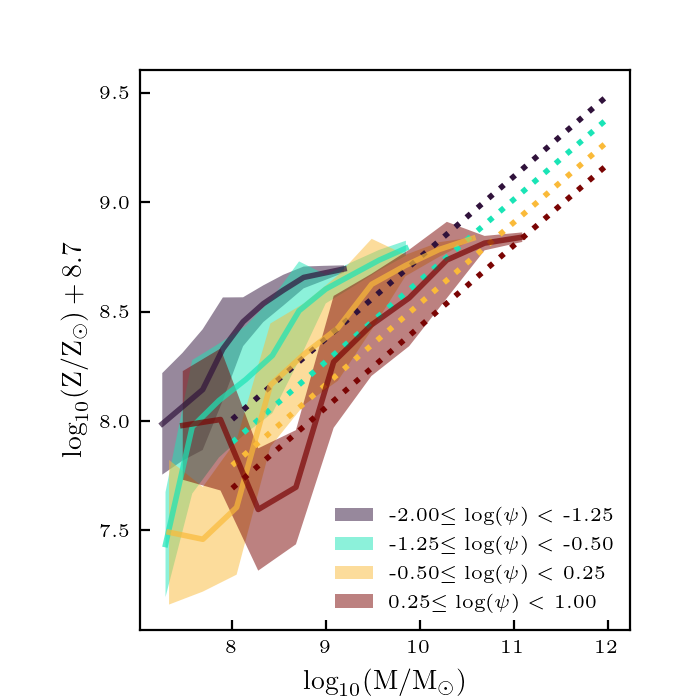
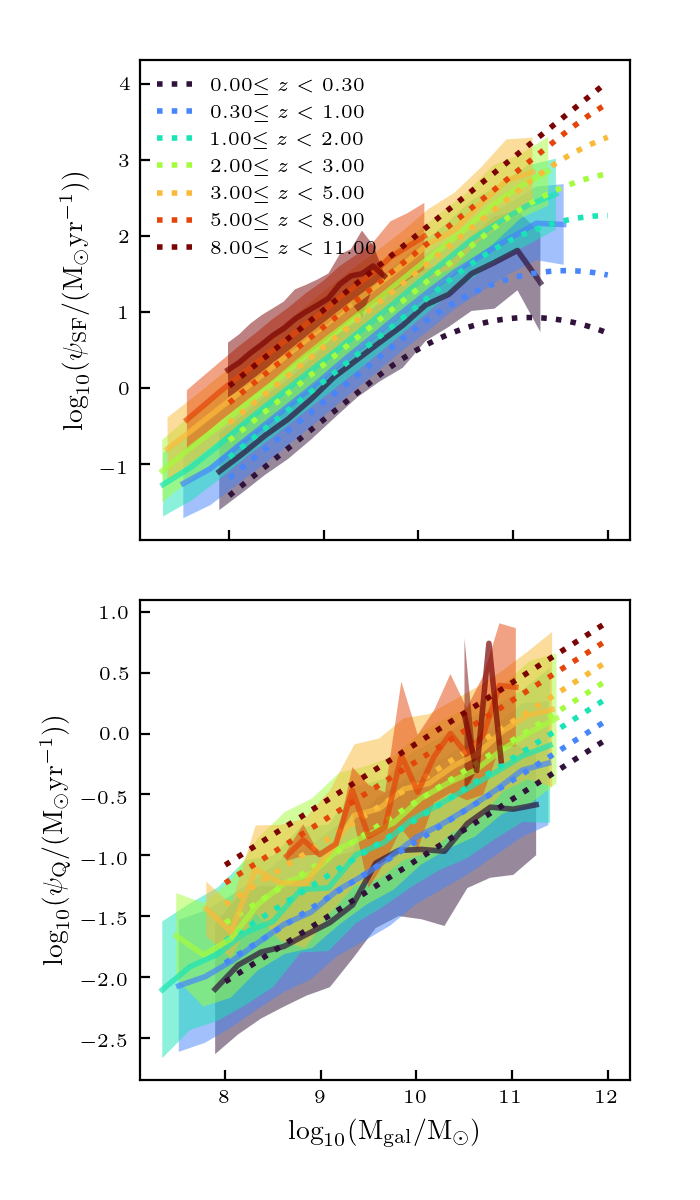
This did not do any better than the 16000 parent catalog in the previous post. The galaxies are too faint, the metallicity too high, and the SFRs are too high.
This could be because parent catalog isn’t sampling parameter space right. I could need more points, or smarter sampling.
To see the distribution of the different parameters, I made a triangle plot, only considering galaxies below redshift \(0.3\) (in both the parent catalog and the galaxy catalog):
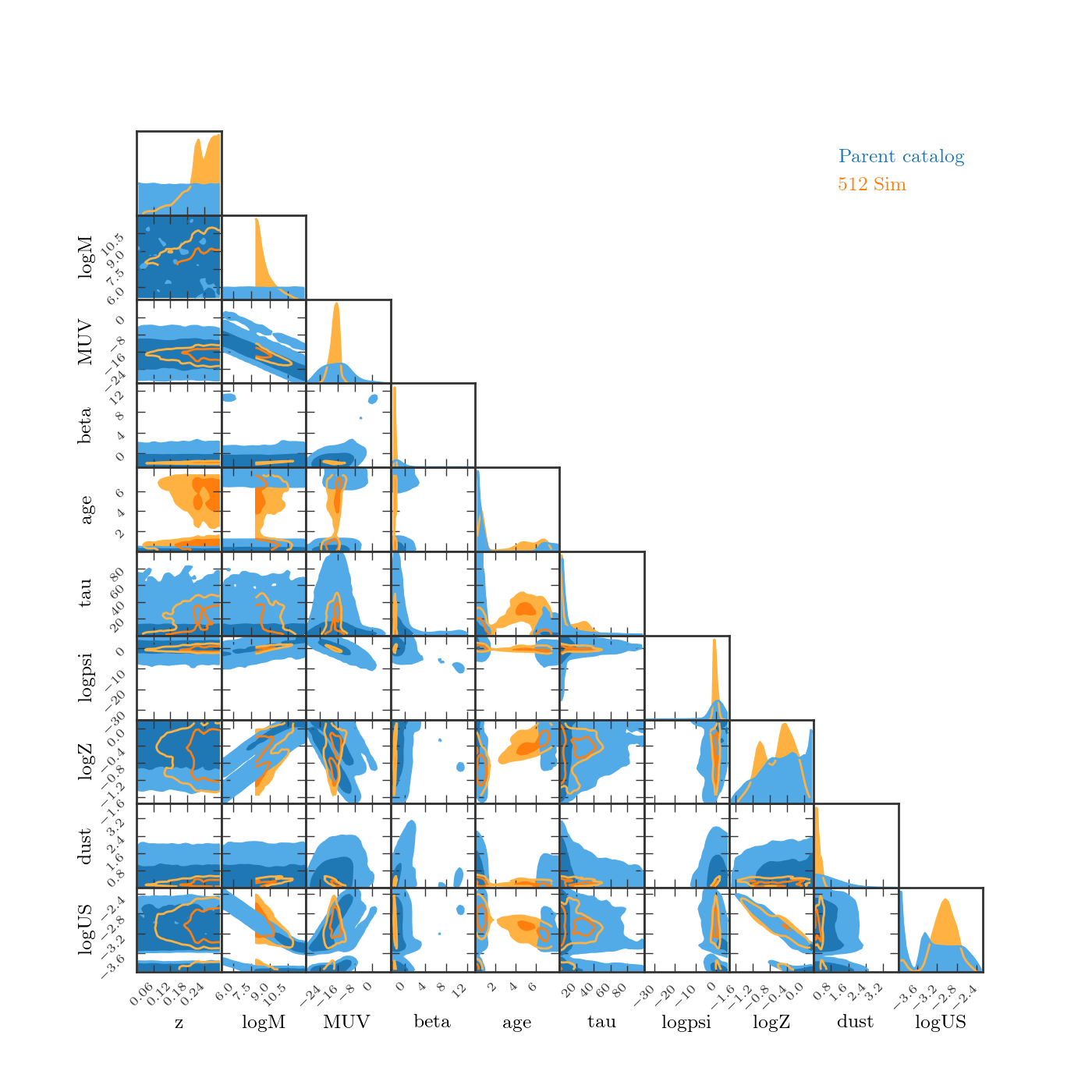
Ages
The age distribution looks strange (note that age is in Gyr in the plot).
As described above, the parent catalog is created from sampling uniformly in log(age/yr) between \(10^6\) years and \(T_{\rm univ} - 10^6\) years, where \(T_{\rm univ}\) is the age of the universe at the specified redshift.
Once the FSPS parameters are assigned from the nearest neighbour in the parent catalog, I ensure that the resulting age is still allowed, by forcing the age to be at the endpoint if it is outside the allowed range.
Possible updates:
- sample uniformly from age in Gyr instead
- only consider nearest neighbours that have permitted ages.
Masses
Another problem is that though I am finding the nearest neighbours, I am then fixing the mass to be the original mass. You can see from this plot that for the \(512^3\) simulations, the minimum mass is much higher than the range in the parent catalog. I pretty sure this is the reason that metallicities are too high.
New workflow
To save the amount of memory that is needed, I am going to restructure the code. This isn’t the most efficient in terms of loading data, but it will limit the amount of data the code needs to store at once. I think with this I should be able to run on 5-10 cores per node, which means I’ll be able to get 160 processes going at once.
Part 1: Make tree
rank 0:
- Load parent catalog
- Sends copy to all processors
All ranks:
- make tree
- delete parent catalog from local memory
- Memory: ~40 GB for 10^8 parent catalog
- Timing: ~20 mins for 10^8 parent catalog
Part 2: Find nearest neighbours
rank 0:
- Read in galaxy catalog info (ONLY mass, redshift, SF)
- Divide among processors
All ranks:
- Propose parameters
- Find 10 nearest neighbours + weights
- Delete tree from local memory
- Memory: ~40 GB for 10^8 parent catalog and 2048 sim
- Timing: ~800 hrs/num_tasks for 2048 sim
Part 3: Get FSPS parameters
rank 0:
- Load parent catalog
- Sends copy to all processors
All ranks:
- calculate the fsps parameters for each galaxy (by weighted average of nearest neighbours)
- delete parent catalog from local memory
- Memory: ~20 GB
- Timing: negligible
- Note: I think I will save the output here, so that Part 4 can be restarted from this point
Part 4: Generate Spectra
rank 0:
- Read in galaxy catalog info
- Assign new fields for magnitudes, SFR, spectra properties, ect.
- Divide among processors
All ranks:
- Save FSPS parameters to galaxy catalog
- Calculate spectra for each galaxy
- Save catalog
- Memory: ~20 GB (but can split this into parts if needed)
- Timing: \(10^4\) hrs/num_tasks
- Note: Since this is the slowest part, and I only need to load in the data that I am calculating spectra for, it might be worth it to code this separately so I can run on 40 nodes per core.
Summary
The last run didn’t work too well. Some possible solutions are:
- Parent catalog: sample more. Right now I am limited to a parent catalog of \(10^6\) galaxies because of memory issues. I rewrote my code as outlined above to allow me to run on a larger parent catalog if needed. I am currently testing this.
- Parent catalog: sample smarter. From the triangle plot above, it seems like the parameter space is sampled fairly well, with the example of galaxy ages that are doing something weird. I am going to change this sampling in the base catalog to be uniform in age [Gyr] rather than in log(age/yr)
- Nearest neighbours/distance calculation: Right now I have normalized parameters mass, redshift, SFR, MUV, beta, metallicity and gas ionization, and am finding the 10 nearest neighbours and normalizing the distance to determine the FSPS parameters dust, age, tau, metallicity and gas ionization. Since the resulting galaxy already has an assigned mass and redshift, this means that if the nearest neighbours are unrealistic (e.g. too small of a mass, or at a redshift that allows for an unrealistic galaxy age), it might not return the desired SFR and UV properties. I need to think a bit about how to change this, either by changing the weighting of the different parameters in the distance calculation, or only considering the nearest neighbours that are close in mass and redshift.
Quiescent Galaxy Assignment
After I get this working, I also have to fix how I am assigning quiescent galaxies.
Right now, every quiescent galaxy has a fixed mass and redshift.
I need 5 more params to assign a spetra from FSPS: dust, gas, metallicity, age, tau.
- dust: right now I am neglecting dust as in Williams et al. 2018; i.e. I am setting it to zero
- gas: this can be neglected for quiescent galaxies. Right now, I am just setting it to a small value, since I don’t think it should affect things much, but I should probably just turn off this module in FSPS.
- SFR: Assign SFR from M-SFR relation (this is related to M, age and tau)
I still need 2 parameters to constrain the spectra. Right now i am randomly sampling age and metallicity within a reasonable range, finding UV-VJ, and rejecting the age/metallicity if it is outside the UVJ box. I do this for a maximum of 10 iterations.
The resulting UVJ diagram looks like this:
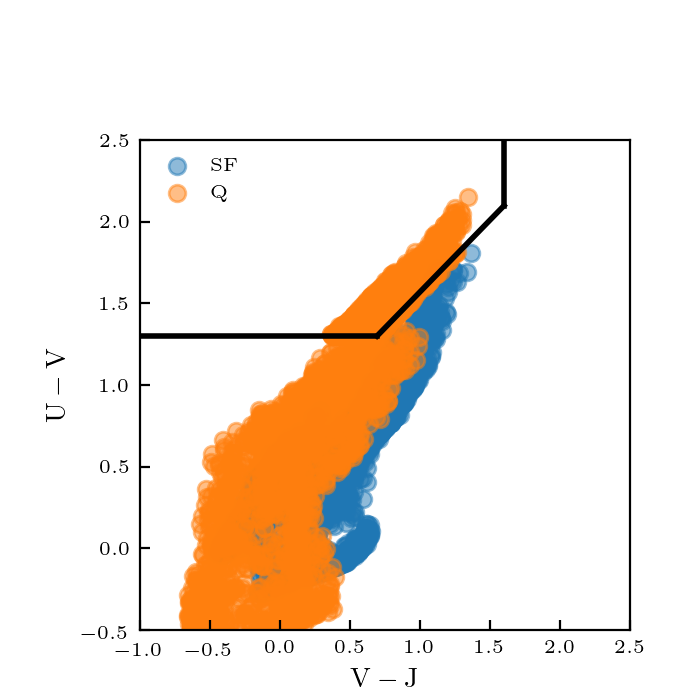
This clearly isn’t right. Including dust could possibly help. For the purposes of this mock catalog, what properties do we want to make sure are correct for the quiescent galaxies?